*Correction* "We didn't go into govt because it was the easy right thing to do, we went into govt because it was the right thing to do"— Liberal Democrats (@LibDems) June 09, 2014
When I started getting interested in food and cooking in the late 1970s, every local community had its own greengrocer, butcher and grocers. I lived in Bruntsfield in Edinburgh and what is now Oddbins was a large fruit and vegetable … Continue reading →
Amazon S3 is designed to provide 99.999999999% durability of objects over a given year. This durability level corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000 objects with Amazon S3, you can on average expect to incur a loss of a single object once every 10,000,000 years. In addition, Amazon S3 is designed to sustain the concurrent loss of data in two facilities.
This is an impressive number, but it's utterly dishonest to make such claims. It implies that there is a less than one-in-one-hundred-billion chance that Amazon will abruptly go out of business, or that a rogue employee will cause massive data loss, or an unexpected bug will result in massive data loss, or a defect in storage media will cause millions of devices to fail silently, or a large solar flare will destroy equipment across three data centers, or that a comet impact will destory three data centers, or that a nuclear exchange will destroy three data centers.
I think these events are all incredibly unlikely, but none of them is one-in-a-hundred-billion unlikely. Yet here is Amazon not only making that argument, but implying that you can safely use S3, a service that launched in 2006, for another ten million years.
Rare events are rare! That's why promises past five or six nines of reliability are functionally meaningless. At that point the "unknown unknowns" must overwhelm any certainty you have about what you think your system is doing.
The risks you failed to model will become obvious in retrospect, and make for an entertaining post-mortem, but that won't get anybody's data back.
Promises like Amazon's should serve as a kind of anti-marketing, suggesting that the company has not thought seriously about the limits of risk assessment and planning.
I suggest the following rule of thumb: if you can't count the number of nines in the reliability claim at a glance, it's specious.
Of course this rant is available in book form, phrased better than I have here. But it's worth repeating at every opportunity.
I’m just kidding. We’re a bunch of literates who enjoy reading so much that we built our own news readers. But when a behemoth like Google makes a call that places you at the business end of 100,000 frantic power users, reminding yourself how tough you are is one way of dealing with the madness.
Google announced Reader’s sunset at 4pm on March 13th, 2013. At that point I had spent three and a half years building my vision of a better news reader. I clearly wasn’t doing it for the money, since my paltry salary didn’t even cover my market rate rent in San Francisco. RSS was a decidedly stupid technology to piggyback off of to try and cover that financial disconnect.
Take a look at this graph. It shows NewsBlur’s income versus its expenses for the past 16 months. Just look at those few months before the Google Reader shutdown announcement in March 2013.
It was never hard to justify to others why I worked on a news reader for three-some years, partially because I’d been justifying it to myself for so long. I had the delusion that it would all work itself out in the end, so long as I kept pushing my hardest and shipping features users wanted. And, at the time, with 1,000 paying subscribers, it certainly felt like I was getting somewhere.
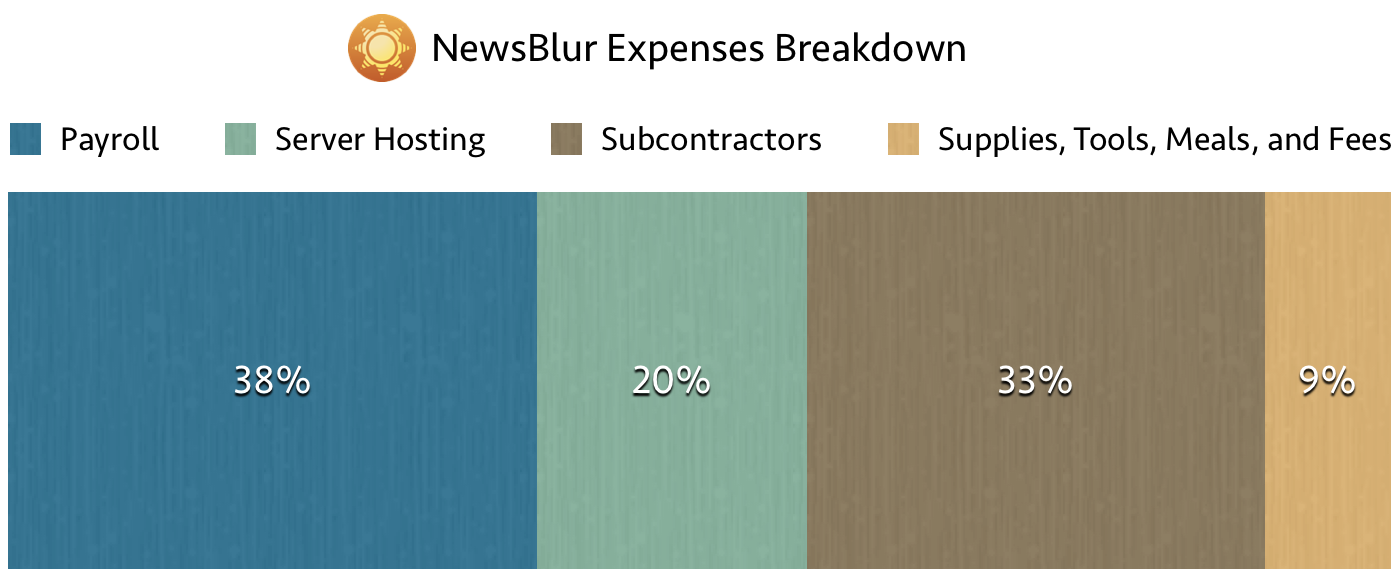
If you’re curious about why expenses are so high, think about what it takes to run a modern and popular news reader. This graph breaks down expenses for an average month from the past year.
Why spend all that money on subcontractors and new tools? Because I’m investing in building an even better news reader.
Fast forward a year and let hindsight tell you what’s what. I was irrational to think that I could make it on my own in a decaying market, what with all the air sucked out by Google. But that three year hallucination kept me persevering to build a better product, which positioned NewsBlur well as a strong candidate for a Reader replacement. When the sunset announcement dropped, it didn’t take long to fortify the servers and handle all the traffic. NewsBlur permanently ballooned up to 20X the number of paid users. People flocked to NewsBlur because it was among the furthest along in creating real competition. As we say on NewsBlur, the people have spoken.
The post-Google Reader landscape
I run a very opinionated news reader. If you think somewhat like I do, you couldn’t be more pleased with the direction NewsBlur goes. But this is still a power tool, and in a world of casual readers who don’t care where their news is coming from so long as it’s in their interests and matches their biases, NewsBlur is the coffee equivalent of the AeroPress. Most people want drip coffee and they don’t bother wasting mental energy on caring about the difference in taste or quality. It’s a binary to them: coffee or no coffee. There’s nothing wrong with that, they just choose to focus on other things more important to them than the sourcing or control they have of their coffee.
Many competing news readers are visual and offer a similar experience. When you want to give up control in exchange for the digested output of sophisticated and heartless algorithms, they’re your best bet. When you want to exert control and know what you want and from which sources, NewsBlur is the only option. No other reader gives you training, statistics, and sharing in one multi-platform app. Nobody else cares so much about RSS as to work on a news reader when it was still a financial inevitability of failure.
Future work on NewsBlur
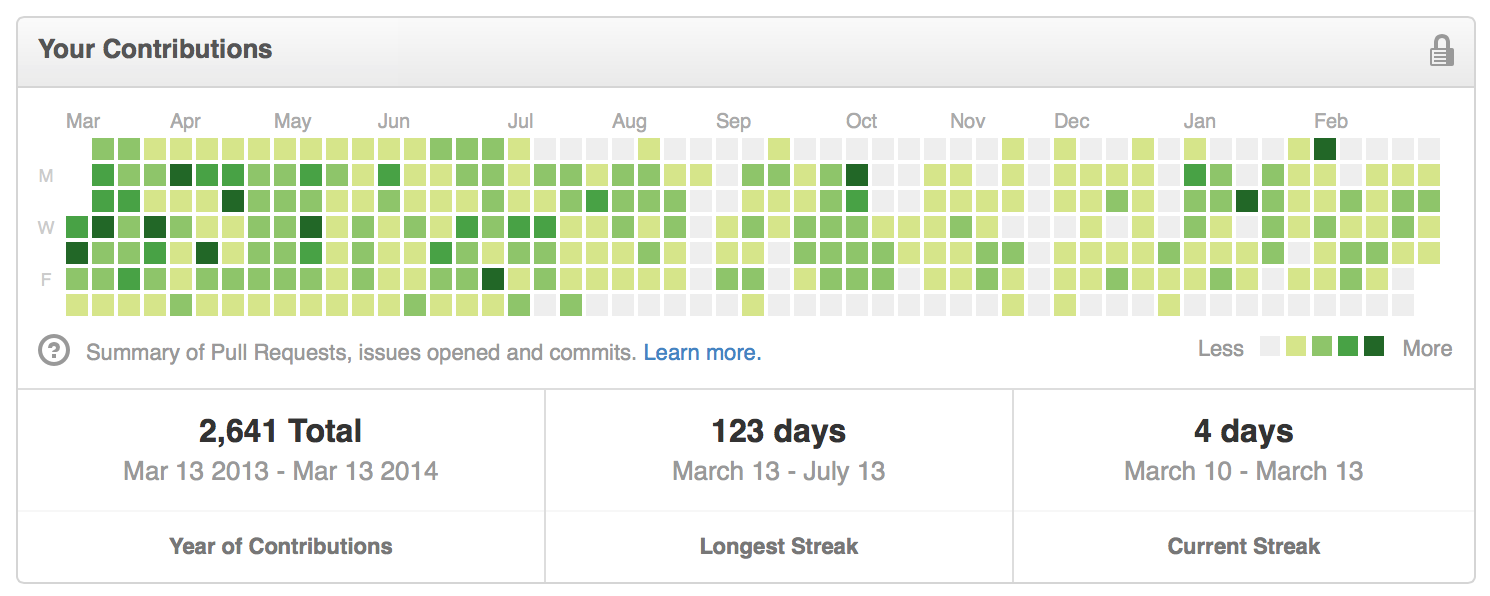
If the past is any indication, NewsBlur is going to continue to see many more improvements. This graph of contributions from the past 365 days shows my level of unwavering dedication.
One way people speak is by committing code to NewsBlur’s GitHub repo. Try developing your own pet feature. I’ll even do some of the hard work for you, so long as you give it a good try and submit a pull request.
Meanwhile, I’m using the windfall to develop a secret project that will complement NewsBlur in a way that hasn’t been tried before with any reader. And if that fails, I’ll find an even better way to make my users happy with their purchase. If you thought I was relentless before March 13th, 2013, just wait until you see what I’m capable of with the finances to build all the big ticket features I’ve been imagining for years.
And while you’re here, do me a favor and tweet about NewsBlur. Tell your followers, who are probably looking for a better way to read news, about how much you rely on NewsBlur. Reading positive tweets about NewsBlur every morning (and afternoon and evening and before bed) make this the best job I’ve ever had.
Newsblur is something worth paying for - I'm very much in the camp of "if you're not paying for it, you're the product" - and I for one prefer to pay for my services directly, rather than by having my data sold.
I like NB so much, I've been developing my own Windows 8 Metro UI for it!
Very happy to have paid for the last year of Newsblur - Google Reader first replaced and since superseded. iOS app continues to improve. Looking forward to more great value in the coming year.
I came to NewsBlur for odd reasons, but I now use it every day and it makes my life actively better. It also allows me to share the writing that's important to me. Thanks, Sam.
With the google reader apocalypse, I was infuriated, because most solutions, both online and offline, always lacked the general usability I needed, especially when it comes to having many feeds. Them Reddit suggested some replacement alternatives. Newsblur was among them. I'm glad I paid attention back them.
Very happy with my decision to move to NewsBlur, even though it was forced upon me by Google pulling Reader. Definitely worth the investment. #newsblur
Feedbin launched into a market with no future. Google owned RSS and they had let it languish.
That all changed when Google announced they were shutting down Google Reader two days after Feedbin launched.
I built Feedbin because I still loved RSS but I didn’t like Google Reader. It looked like it had been abandoned after the last update in 2011 that attempted to prop up Google+ by removing many features.
The goal was to be able to cover costs in one year. Instead it took three weeks. It cost about $170/month to run Feedbin when it launched and with $1.62/user/month in profit after credit card fees it looked like I would need just over 100 customers who were also looking for a Google Reader alternative.
Feedbin has one of those boring business models that actually works. Charging money for a good or service. Feedbin will never have millions of customers but that’s OK. It just needs you.
Timing was everything for Feedbin’s success. I think having a halfway decent product only went so far as to not actively hurt Feedbin’s chances. Of course Google Reader closing was the event that started it all, but gaining Reeder support early on gave Feedbin a built in audience.
Scaling
Getting so much interest was exciting but also extremely challenging. Feedbin had scaling problems within the first few weeks as the number of feeds to refresh went up. For feed refreshing Mike Perham’sSidekiq was critical to getting acceptable refresh times. It’s the fastest and least memory intensive background job processor I’ve used and it keeps getting better and better. Feedbin would have been tougher to build without it.
Scaling the background stuff was possible thanks to Sidekiq, but scaling the web facing side was more stressful. Feedbin was hosted on Heroku for the first four months. I was frequently turning on more front-end servers (dynos) and bumping up the database plan. Once I was on the highest-end $6,400/month PostgreSQL plan, I knew I needed to try something else because there was nowhere else to go on Heroku.
I’ve heard Ruby isn’t the fastest language and I’m sure my code could have been improved, but the performance didn’t add up. I also still had a full time job at Flickerbox back then so I didn’t have time to diagnose what was going on.
With a copy of the production database running locally on an 11-inch MacBook Air, pages took a fraction of the time to load. The biggest difference between that environment and production was a solid-state drive. At the time Amazon did not offer any SSD options so I suspected Heroku Postgres was held back by running on spinning disks.
I started to look into dedicated hosting that had some hardware flexibility and settled on SoftLayer. If you’ve never used a dedicated server before it’s a breath of fresh air coming from AWS or any VPS. All those problems of noisy neighbors, poor I/O, weird LAN latency or other networking anomalies just go away. Oh yeah and it’s fast.
Response time for critical pages (left before move, right after move)
On the day of the move people asked why Feedbin had to move on a weekday and the reason was that I didn’t think I had a choice. I was looking at these graphs pretty sure that Feedbin was about to fall over.
For all this performance, surely the price must have gone way up? Well no. Feedbin’s last bill on Heroku was for $7,997 and the first month’s bill on SoftLayer was $3,932 so dedicated does not mean expensive.
Design
One of the things I’m most proud of about Feedbin is the design. The design has always been a collaboration between Todd J. Collins and I. In the beginning it was more me, but starting with the redesign Todd has set the visual direction, which explains why it’s gotten so good. Todd and I get together most Mondays to plan and design new features. For such a short window of time I think we get a lot done.
The design has evolved since my crude, static HTML mockups.
Early Feedbin HTML Mockup (October 2012)Feedbin at Launch (March 2013)Feedbin Now (March 2014)
The RSS Market
I have no doubt that RSS is better for Google having folded their offering. There’s so much choice now that it’s actually a crowded market. It’s also an area that attracts a lot of developers because everybody thinks they can build one (and they’re right).
RSS is one of the last holdouts of a more open web and it’s been gratifying to see that there’s enough interest in it to sustain some great independent services that care more about the product than eyeballs.
The next time you read somebody declaring the death of RSS, you can just smile to yourself as you mark it as read in your favorite reader and move on to the next article.